HashMap
1、HashMap 的内部数据结构
目前我用的是 JDK1.8 版本的,内部使用数组 + 链表 / 红黑树链表大于8转换成红黑数,红黑树节点小于6退化为链表
2、HashMap插入数据流程
判断数组是否为空,为空进行初始化;
不为空,计算 k 的 hash 值,通过 (n - 1) & hash计算应当存放在数组中的下标 index ;
查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
存在数据,说明发生了hash冲突, 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创建树型节点插入红黑树中;
如果不是树型节点,创建普通Node加入链表中;
判断链表长度是否大于 8,并且数组长度大于64, 大于的话链表转换为红黑树(),
链表长度大于8,数据组长度小于64,先进行resize()
插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍
注意:
JDK 1.8 引入了红黑树,当链表的长度大于 8 的时候就会转换为红黑树,不过,在转换之前,会先去查看 table 数组的长度是否大于 64,如果数组的长度小于 64,那么 HashMap 会优先选择对数组进行扩容 **resize**,而不是把链表转换成红黑树,进行resize时当红黑树节点小于6时,转换成链表
1 | //onlyIfAbsent 是否覆盖key相同值,true 覆盖,默认false |
2、HashMap获取流程
获取原生key的hash, (n-1)&hash 计算节点存储index
获取tab[index] 是否存在,不存在返回null
存在比较key值是否相等,相等返回值
key值数组首节点不相等,获取首节点next节点,next为空返回null
遍历根据类型变量next节点
为ListNode则遍历查找
为treeNode节点则 当前节点hash是否大于
3、HashMap的哈希函数怎么设计
hash函数是先拿到通过key 的hashcode,是32位的int值,然后让hashcode的高16位和低16位进行异或操作。
扰乱函数优点:
一定要尽可能降低hash碰撞,越分散越好;
算法一定要尽可能高效,因为这是高频操作,位运算更高效
Java1.8相比1.7做了调整,1.7做了四次移位和四次异或,但明显Java 8觉得扰动做一次就够了,做4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次。
4、java8优化
数组+链表改成了数组+链表或红黑树;
链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后;
扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩
5、HashMap 在 JDK 1.7 和 JDK 1.8 中为什么不安全:
JDK 1.7:由于采用头插法改变了链表上元素的的顺序,并发环境下扩容可能导致循环链表的问题
JDK 1.8:由于 put 操作并没有上锁,并发环境下可能发生某个线程插入的数据被覆盖的问
6、如何保证 HashMap 线程安全?
使用 java.util.Collections 类的 synchronizedMap 方法包装一下 HashMap,得到线程安全的 HashMap,其原理就是对所有的修改操作都加上 synchronized
使用线程安全的 HashTable 类代替,该类在对数据操作的时候都会上锁,也就是加上 synchronized
使用线程安全的 ConcurrentHashMap 类代替,该类在 JDK 1.7 和 JDK 1.8 的底层原理有所不同,JDK 1.7 采用数组 + 链表存储数据,使用分段锁 Segment 保证线程安全;JDK 1.8 采用数组 + 链表/红黑树存储数据,使用 CAS + synchronized 保证线程安全。
7、HashMap 是否有序
hashMap无序因为hashCode冲突,要实现按插入顺序输出需要LinkHashMap,treeMap
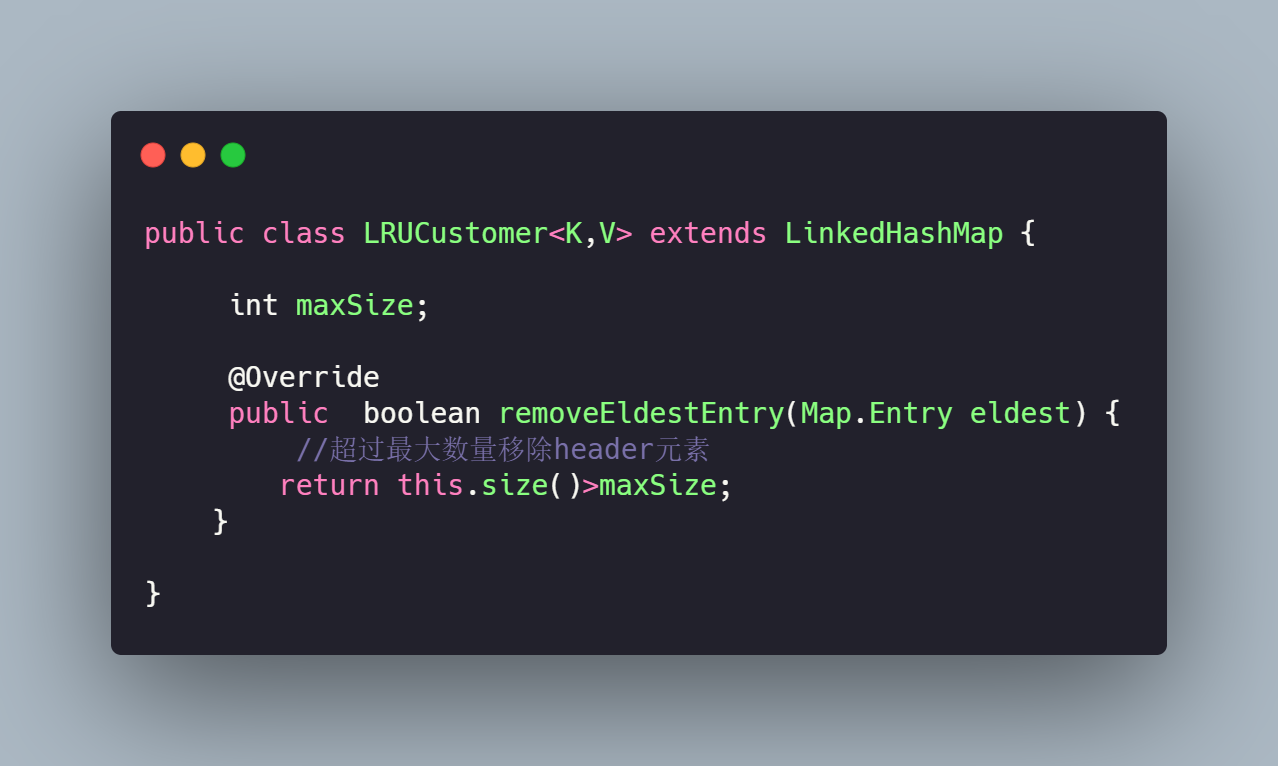
LinkHashMap
数据结构双向链表
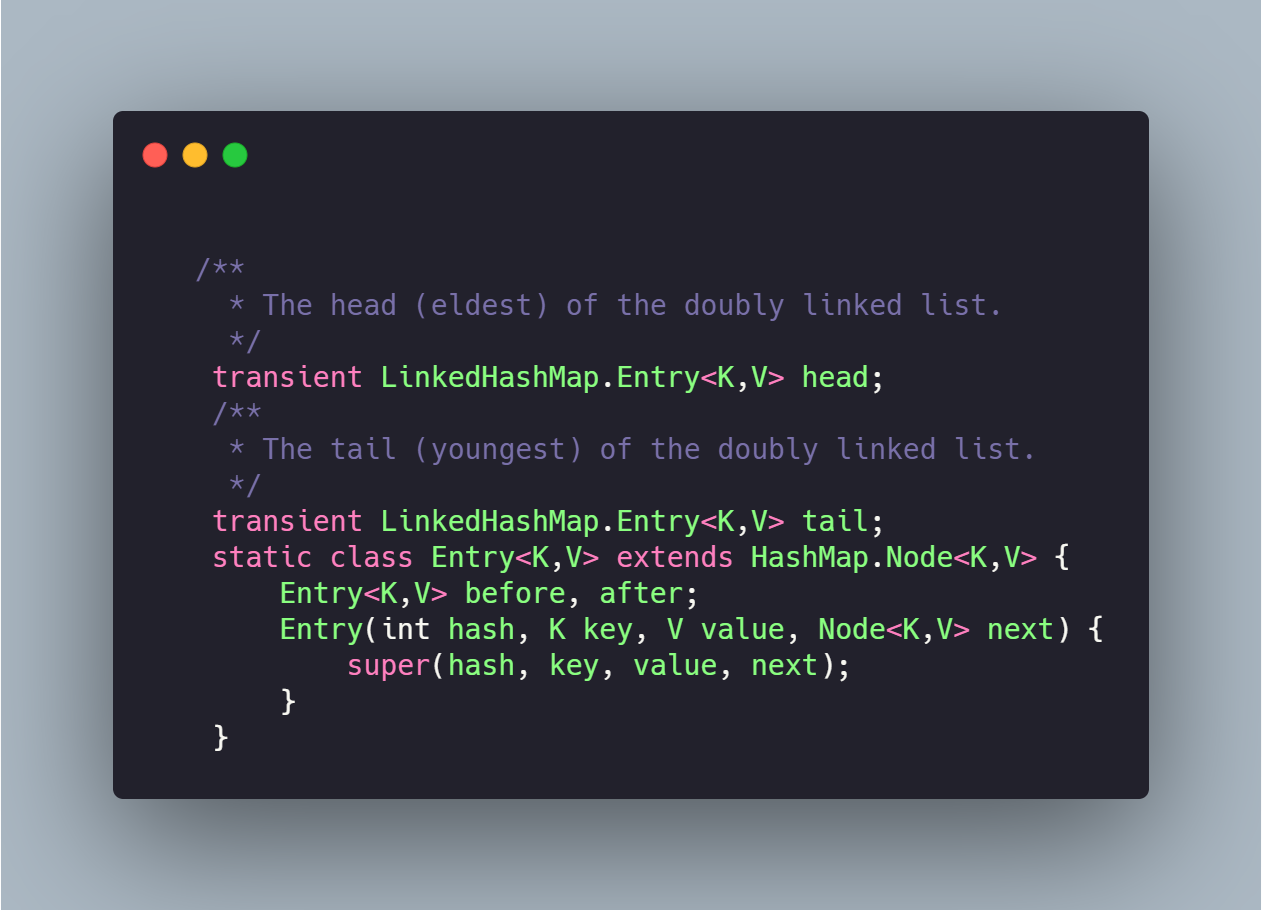 实现
实现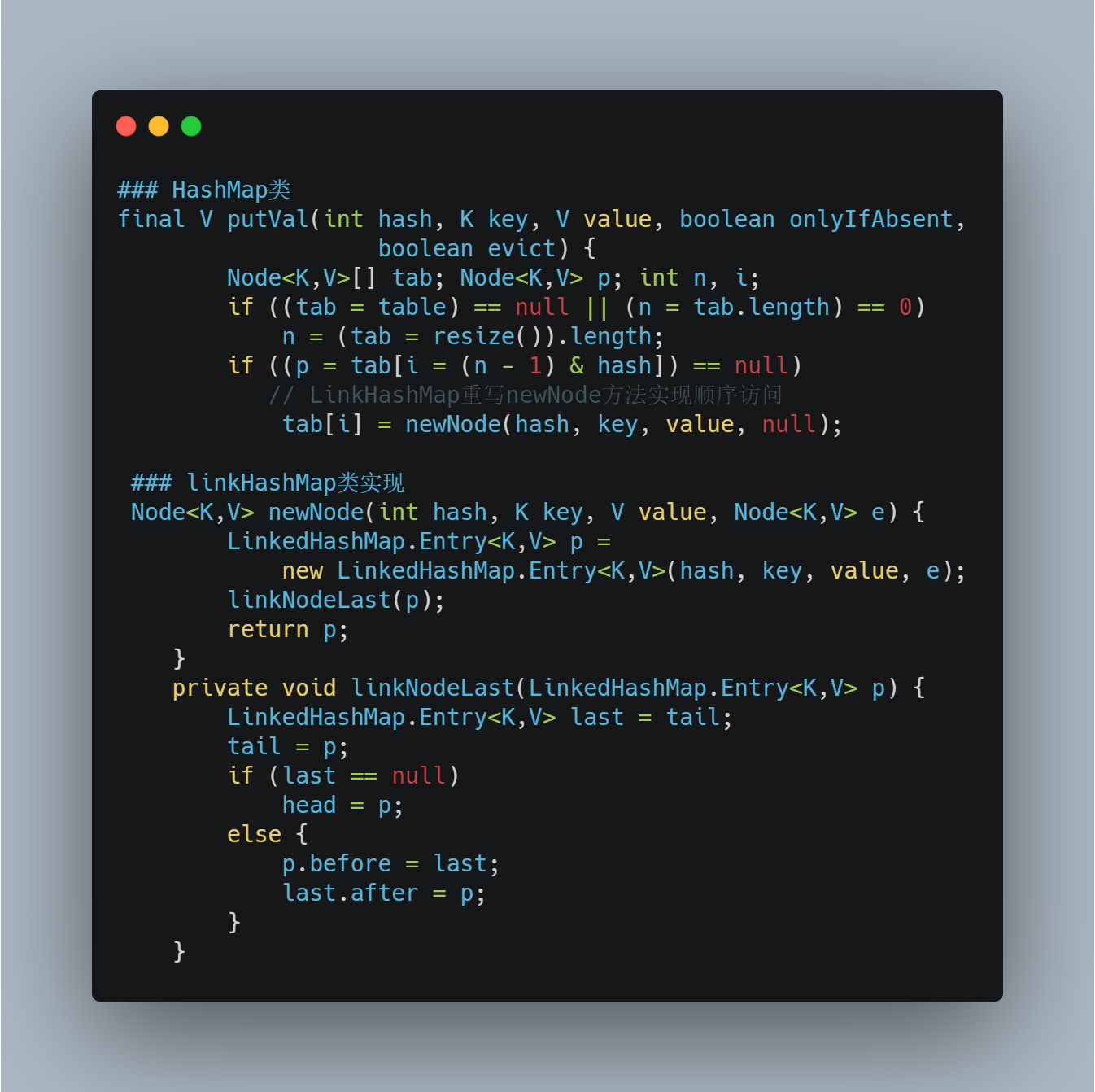
8、基于LinkHashMap 实现LRU