分布式事务
XA 协议
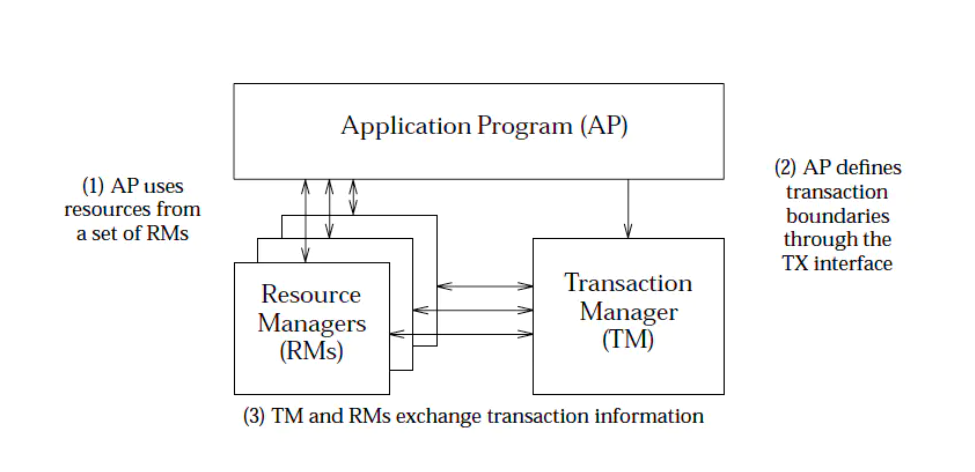
XA协议是使用了二阶段协议的,其中:
- 第一阶段TM要求所有的RM准备提交对应的事务分支,询问RM是否有能力保证成功的提交事务分支,RM根据自己的情况,如果判断自己进行的工作可以被提交,那就就对工作内容进行持久化,并给TM回执OK;否者给TM的回执NO。RM在发送了否定答复并回滚了已经的工作后,就可以丢弃这个事务分支信息了。
- 第二阶段TM根据阶段1各个RM prepare的结果,决定是提交还是回滚事务。如果所有的RM都prepare成功,那么TM通知所有的RM进行提交;如果有RM prepare回执NO的话,则TM通知所有RM回滚自己的事务分支。
方案缺点:
该方案的缺陷:
同步阻塞:所有的参与者都是事务同步阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
单点故障:一旦协调器发生故障,系统不可用。
数据不一致:当协调器发送commit之后,有的参与者收到commit消息,事务执行成功,有的没有收到,处于阻塞状态,这段时间会产生数据不一致性。
不确定性:当协调器发送commit之后,并且此时只有一个参与者收到了commit,那么当该参与者与协调器同时宕机之后,重新选举的协调器无法确定该条消息是否提交成功。
角色
- 事务参与者
- 事务协调者
- 资源管理器 RM
- 事务管理器 TM
方案
1. 2Pc 和 3PC
2PC过程
1)准备阶段:事务协调者向各个事务参与者发起询问请求:“我要执行全局事务了,这个事务涉及到的资源分布在你们这些数据源中,分别是……,你们准备好各自的资源(即各自执行本地事务到待提交阶段)”。各个参与者协调者回复 yes(表示已准备好,允许提交全局事务)或 no(表示本参与者无法拿到全局事务所需的本地资源,因为它被其他本地事务锁住了)或超时。
2)提交阶段:如果各个参与者回复的都是 yes,则协调者向所有参与者发起事务提交操作,然后所有参与者收到后各自执行本地事务提交操作并向协调者发送 ACK;如果任何一个参与者回复 no 或者超时,则协调者向所有参与者发起事务回滚操作,然后所有参与者收到后各自执行本地事务回滚操作并向协调者发送 ACK。
2PC存在问题
1)性能差,在准备阶段,要等待所有的参与者返回,才能进入阶段二,在这期间,各个参与者上面的相关资源被排他地锁住,参与者上面意图使用这些资源的本地事务只能等待。因为存在这种同步阻塞问题,所以影响了各个参与者的本地事务并发度
2)准备阶段完成后,如果协调者宕机,所有的参与者都收不到提交或回滚指令,导致所有参与者“不知所措”
3)在提交阶段,协调者向所有的参与者发送了提交指令,如果一个参与者未返回 ACK,那么协调者不知道这个参与者内部发生了什么(由于网络二将军问题的存在,这个参与者可能根本没收到提交指令,一直处于等待接收提交指令的状态;也可能收到了,并成功执行了本地提交,但返回的 ACK 由于网络故障未送到协调者上),也就无法决定下一步是否进行全体参与者的回滚。
4) 使用参与者实现XA协议
3pc : 询问阶段、准备阶段、提交或回滚阶段 ,参与者加入超时机制,解决2pc同步阻塞问题和避免资源被永久锁定
CanCommitPreCommitdo Commit
2. TCC
1)阶段一:准备阶段。协调者调用所有的每个微服务提供的 try 接口,将整个全局事务涉及到的资源锁定住,若锁定成功 try 接口向协调者返回 yes。
2)阶段二:提交阶段。若所有的服务的 try 接口在阶段一都返回 yes,则进入提交阶段,协调者调用所有服务的 confirm 接口,各个服务进行事务提交。如果有任何一个服务的 try 接口在阶段一返回 no 或者超时,则协调者调用所有服务的 cancel 接口。
失败重试,接口幂等
接口幂等方案: 每个参与者可以维护一个去重表(可以利用数据库表实现也可以使用内存型 KV 组件实现),记录每个全局事务(以全局事务标 XID 区分)是否进行过 confirm 或 cancel 操作,若已经进行过,则不再重复执行。
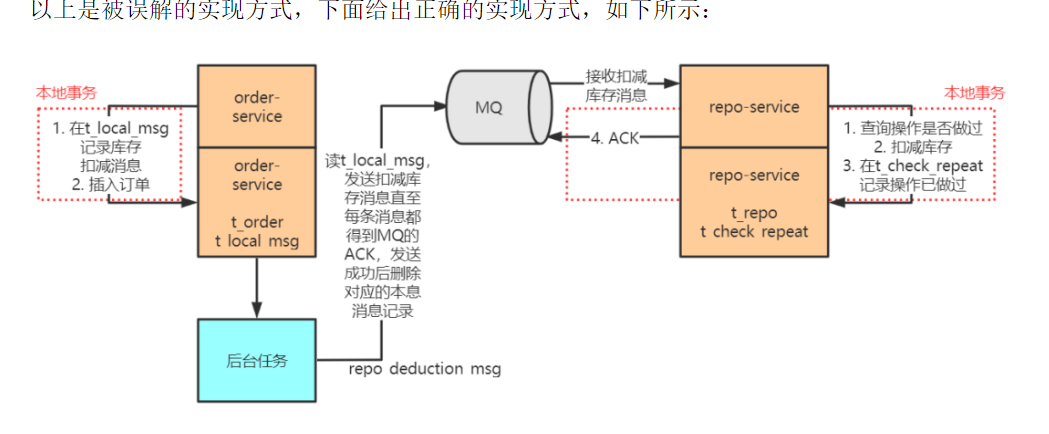
3.事务状态表方案
假设要在一个分布式事务中实现调用repo-service扣减库存、调用 order-service 生成订单两个过程。在这种方案中,协调者 shopping-service 维护一张如下的事务状态表:
| 分布式事务 ID | 事务内容 | 事务状态 |
|---|---|---|
global_trx_id_1 |
操作 1:调用 repo-service 扣减库存 操作 2:调用 order-service 生成订单 |
状态 1:初始 状态 2:操作 1 成功 状态 3:操作 1、2 成功 |
初始状态为 1,每成功调用一个服务则更新一次状态,最后所有的服务调用成功,状态更新到 3。
有了这张表,就可以启动一个后台任务,扫描这张表中事务的状态,如果一个分布式事务一直(设置一个事务周期阈值)未到状态 3,说明这条事务没有成功执行,于是可以重新调用 repo-service 扣减库存、调用 order-service 生成订单。直至所有的调用成功,事务状态到 3。
如果多次重试仍未使得状态到 3,可以将事务状态置为 error,通过人工介入进行干预。
4 .基于消息中间件的最终一致性事务方案
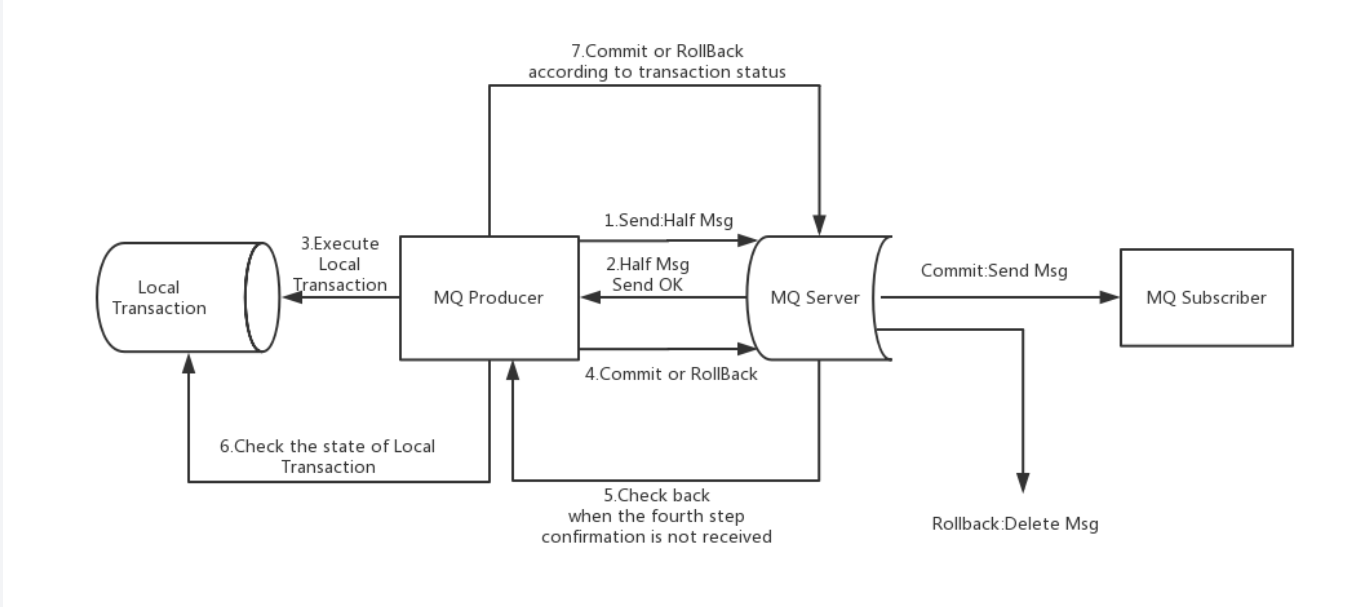
一种是基于MQ的事务消息
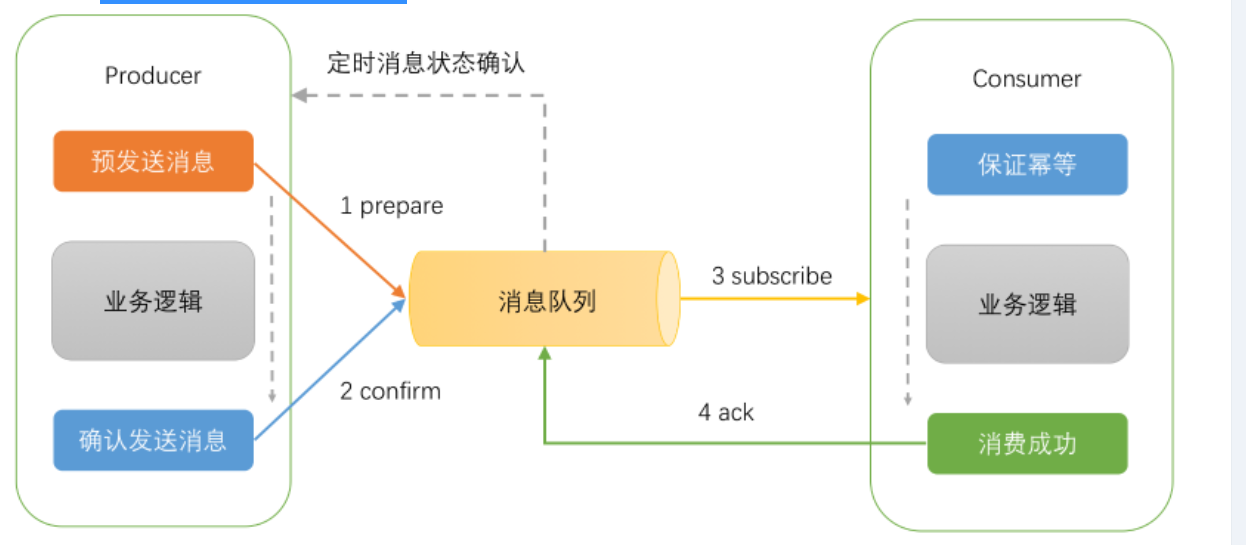
RocketMQ在4.3.0版中已经支持分布式事务消息,采用了2PC(两阶段提交)+ 补偿机制(事务状态回查)的思想来实现了提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息
开源分布式事务框架 Seata 的实现
1.Seata包含以下几个核心组件
- Transaction Coordinator(TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
- Transaction Manager(TM):控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
- Resource Manager(RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
2. 实现
整体流程
- 事务开启时,TM向TC注册全局事务,并且获得全局事务
XID - 这时候多个微服务的接口发生调用,
XID就会传播到各个微服务中,每个微服务执行事务也会向TC注册分支事务。 - 之后TM就可以管理针对每个
XID的事务全局提交和回滚,RM完成分支的提交或者回滚。
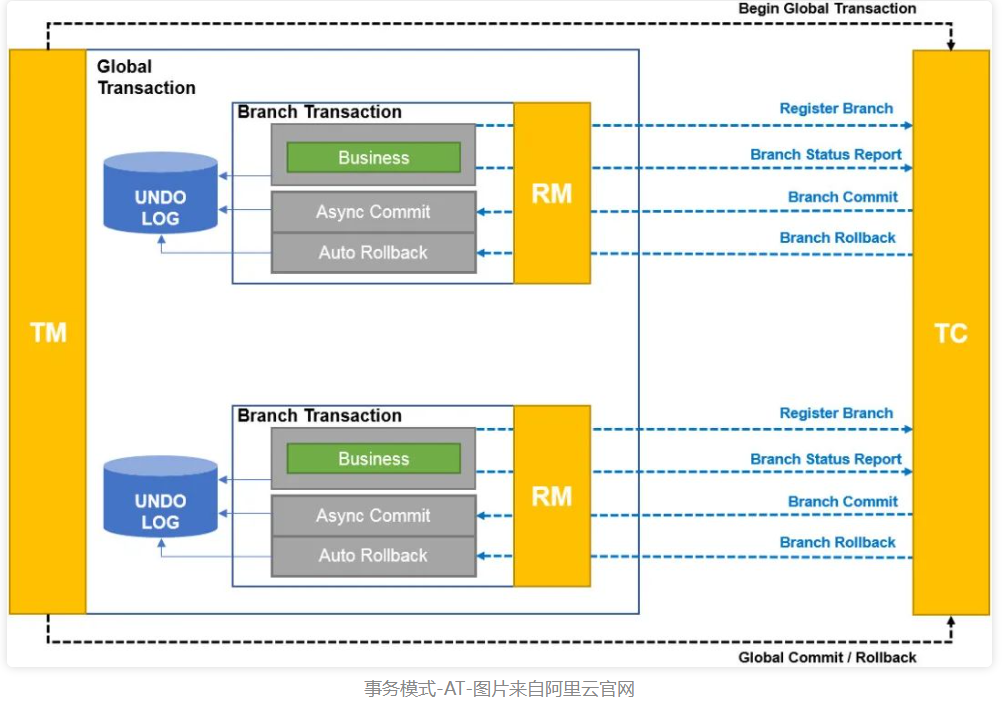
AT模式
- TM向TC注册全局事务,获得
XID - RM则会去代理
JDBC数据源,生成镜像的SQL,形成UNDO_LOG,然后向TC注册分支事务,把数据更新和UNDO_LOG在本地事务中一起提交 - TC如果收到commit请求,则会异步去删除对应分支的UNDO_LOG,如果是rollback,就去查询对应分支的UNDO_LOG,通过UNDO_LOG来执行回滚
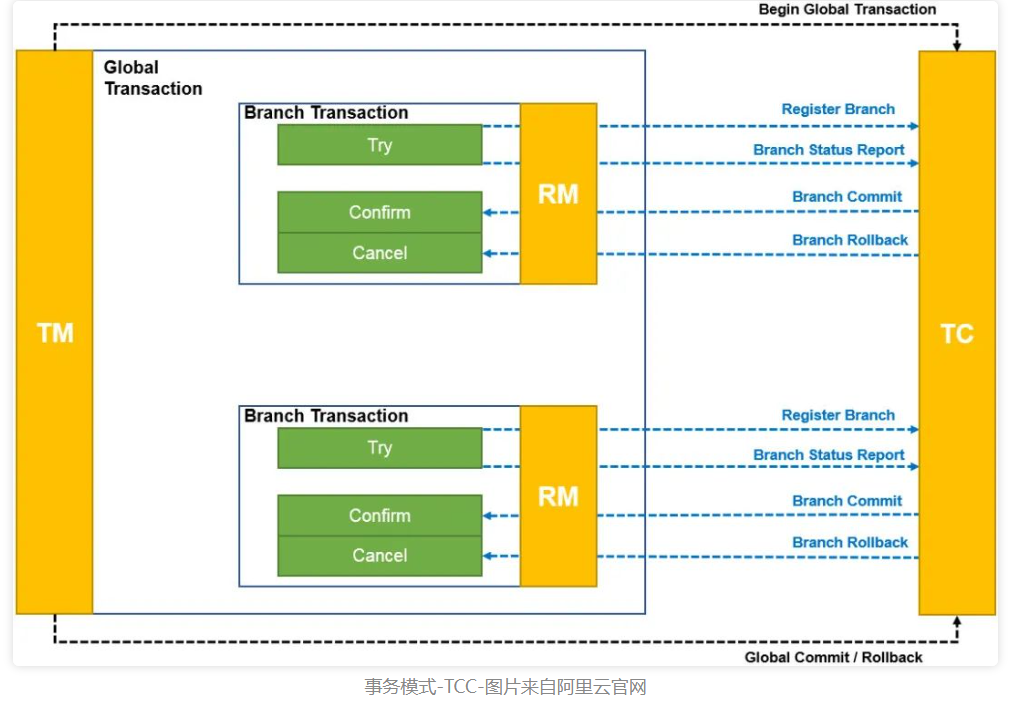
TCC模式
相比AT模式代理JDBC数据源生成UNDO_LOG来生成逆向SQL回滚的方式,TCC就更简单一点了。
- TM向TC注册全局事务,获得
XID - RM向TC注册分支事务,然后执行Try方法,同时上报Try方法执行情况
- 然后如果收到TC的commit请求就执行Confirm方法,收到rollback则执行Cancel
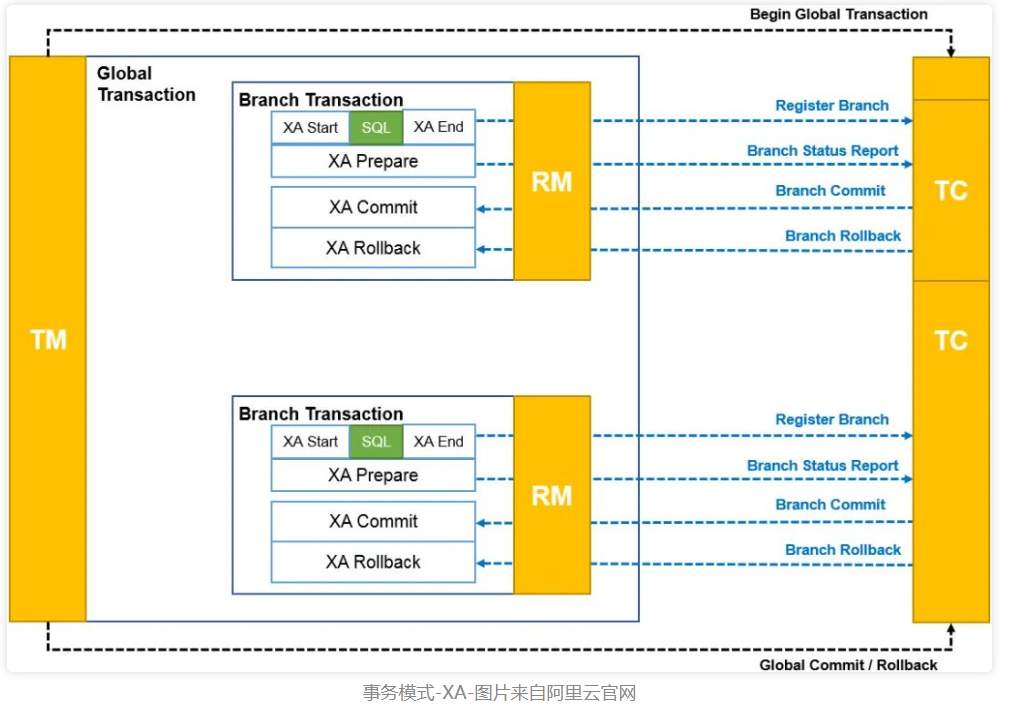
XA模式
- TM向TC注册全局事务,获得
XID - RM向TC注册分支事务,
XAStart,执行SQL,XA END,XA Prepare,然后上报分支执行情况 - 然后如果收到TC的commit请求就执行Confirm方法,收到rollback则执行Cancel