分布式锁
1. zookeeper 实现
Zookeeper是通过创建临时顺序节点的方式来实现。
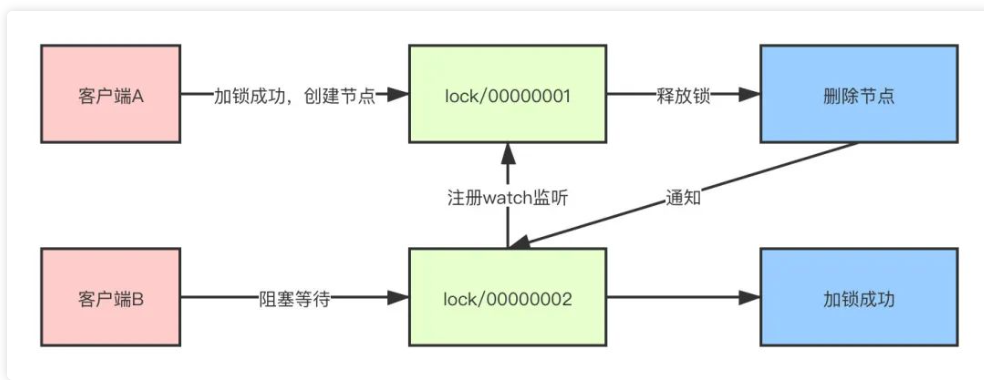
- 当需要对资源进行加锁时,实际上就是在父节点之下创建一个临时顺序节点。
- 客户端A来对资源加锁,首先判断当前创建的节点是否为最小节点,如果是,那么加锁成功,后续加锁线程阻塞等待
- 此时,客户端B也来尝试加锁,由于客户端A已经加锁成功,所以客户端B发现自己的节点并不是最小节点,就会去取到上一个节点,并且对上一节点注册监听
- 当客户端A操作完成,释放锁的操作就是删除这个节点,这样就可以触发监听事件,客户端B就会得到通知,同样,客户端B判断自己是否为最小节点,如果是,那么则加锁成功。
2. redis 方案
redis setNX EX :
NX 代表如果要设置的key已存在,则取消设置
EX 代表过期时间为秒,PX则为毫秒
2.1 锁超时问题和锁误删
客户A加锁成功3秒,业务流程执行超过3秒,锁释放,客户B申请锁成功,客户A执行完释放锁,导致释放B申请的锁。
锁超时:
- 评估业务设置合适的超时时间
- 自动续期,通过其他线程为将要过期的线程续期
锁误删:
- set 时 生成唯一id,只解锁自己申请的锁,通过
lua脚本解锁
2.2 RedLock算法
因为在Redis的主从架构下,主从同步是异步的,如果在Master节点加锁成功后,指令还没有同步到Slave节点,此时Master挂掉,Slave被提升为Master,新的Master上并没有锁的数据,其他的客户端仍然可以加锁成功
RedLock的理念下需要至少2个Master节点,多个Master节点之间完全互相独立,彼此之间不存在主从同步和数据复制
- 获取当前Unix时间
- 按照顺序依次尝试从多个节点锁,如果获取锁的时间小于超时时间,并且超过半数的节点获取成功,那么加锁成功。这样做的目的就是为了避免某些节点已经宕机的情况下,客户端还在一直等待响应结果。举个例子,假设现在有5个节点,过期时间=
100ms,第一个节点获取锁花费10ms,第二个节点花费20ms,第三个节点花费30ms,那么最后锁的过期时间就是100-(10+20+30),这样就是加锁成功,反之如果最后时间<0,那么加锁失败 - 如果加锁失败,那么要释放所有节点上的锁
RedLock 存在问题
- 性能、资源 : 对多个节点加锁,耗时加长
- 节点崩溃重启
比如有1~5号五个节点,并且没有开启持久化,客户端A在1,2,3号节点加锁成功,此时3号节点崩溃宕机后发生重启,就丢失了加锁信息,客户端B在3,4,5号节点加锁成功。
Redis作者建议的方式就是延时重启,比如3号节点宕机之后不要立刻重启,而是等待一段时间后再重启,这个时间必须大于锁的有效时间,也就是锁失效后再重启,这种人为干预的措施真正实施起来就比较困难了- 第二个方案那么就是开启持久化,但是这样对性能又造成了影响。比如如果开启
AOF默认每秒一次刷盘,那么最多丢失一秒的数据,如果想完全不丢失的话就对性能造成较大的影响。
GC、网络延迟
client1线程获取到锁,然后发生GC停顿,超过了锁的有效时间导致锁被释放,然后锁被client2拿到,然后两个客户端同时拿到锁在写数据,问题产生。
- 时钟跳跃
假设发生网络分区,4、5号节点变为一个独立的子网,3号节点发生始终跳跃(不管人为操作还是同步导致)导致锁过期,这时候另外的客户端就可以从3、4、5号节点加锁成功,问题又发生了。
2.3 终极方案 redission
支持单机,集群,哨兵
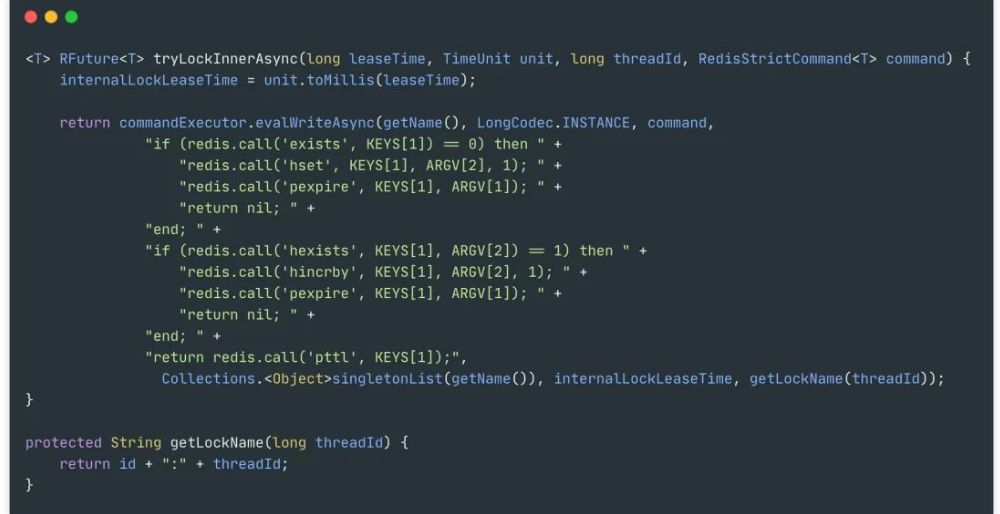
1.加锁
2. 释放锁
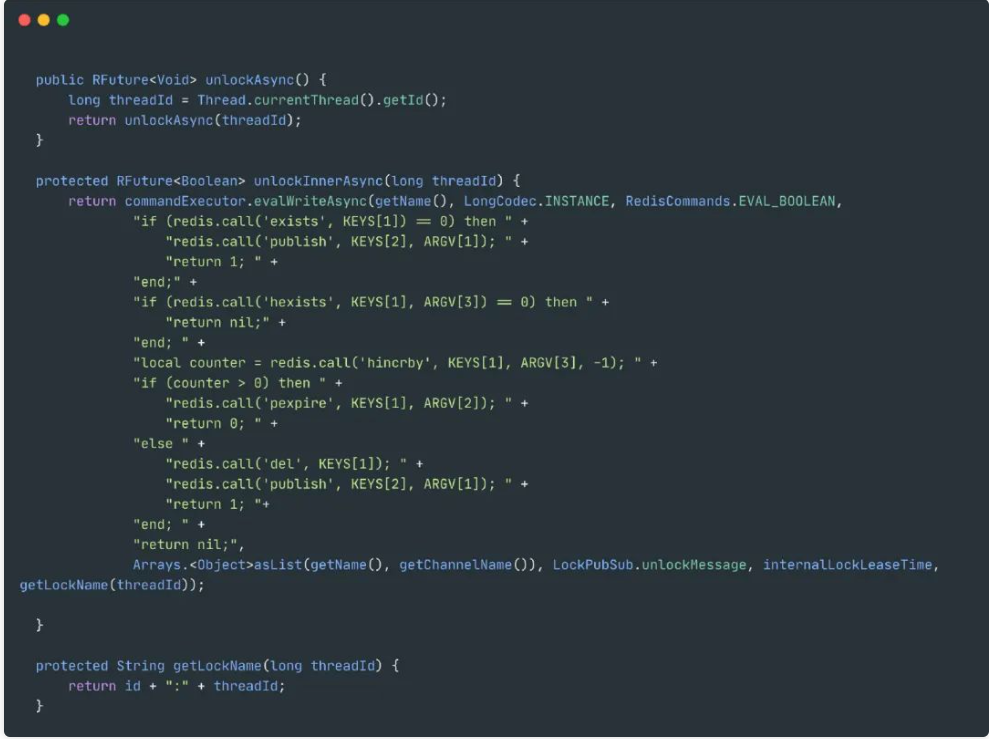
- 如果key都不存在了,那么就直接返回
- 如果key、field不匹配,那么说明不是自己的锁,不能释放,返回空
- 释放锁,重入次数-1,如果还大于0那么久刷新过期时间,反之那么久删除锁
3. watchdog
解决了锁超时导致的问题,实际上就是一个后台线程,默认每隔10秒自动延长锁的过期时间。
默认的时间就是internalLockLeaseTime / 3,internalLockLeaseTime默认为30秒。只有不指定锁定时间时生效。
3. 基于关系型数据库
3.1 悲观锁
1 | select id from order where order_id = xxx for update |
注意:基于 MySQL 行锁的方式会出现交叉死锁, 通过超时机制解决死锁问题,高并发会出现排队现象,存在性能缺陷
3.2 基于乐观锁方案
1 | select amount, old_ver from order where order_id = xxx |